
Introducing astjson: Transform and Merge JSON Objects with Unmatched Speed in Go

Jens Neuse
In this article, I will introduce you to a new package called astjson that I have been working on for the last couple of weeks. It is a Go package that allows you to transform and merge JSON objects with unmatched speed. It is based on the jsonparser package by buger aka Leonid Bugaev and extends it with the ability to transform and merge JSON objects at unparalleled performance.
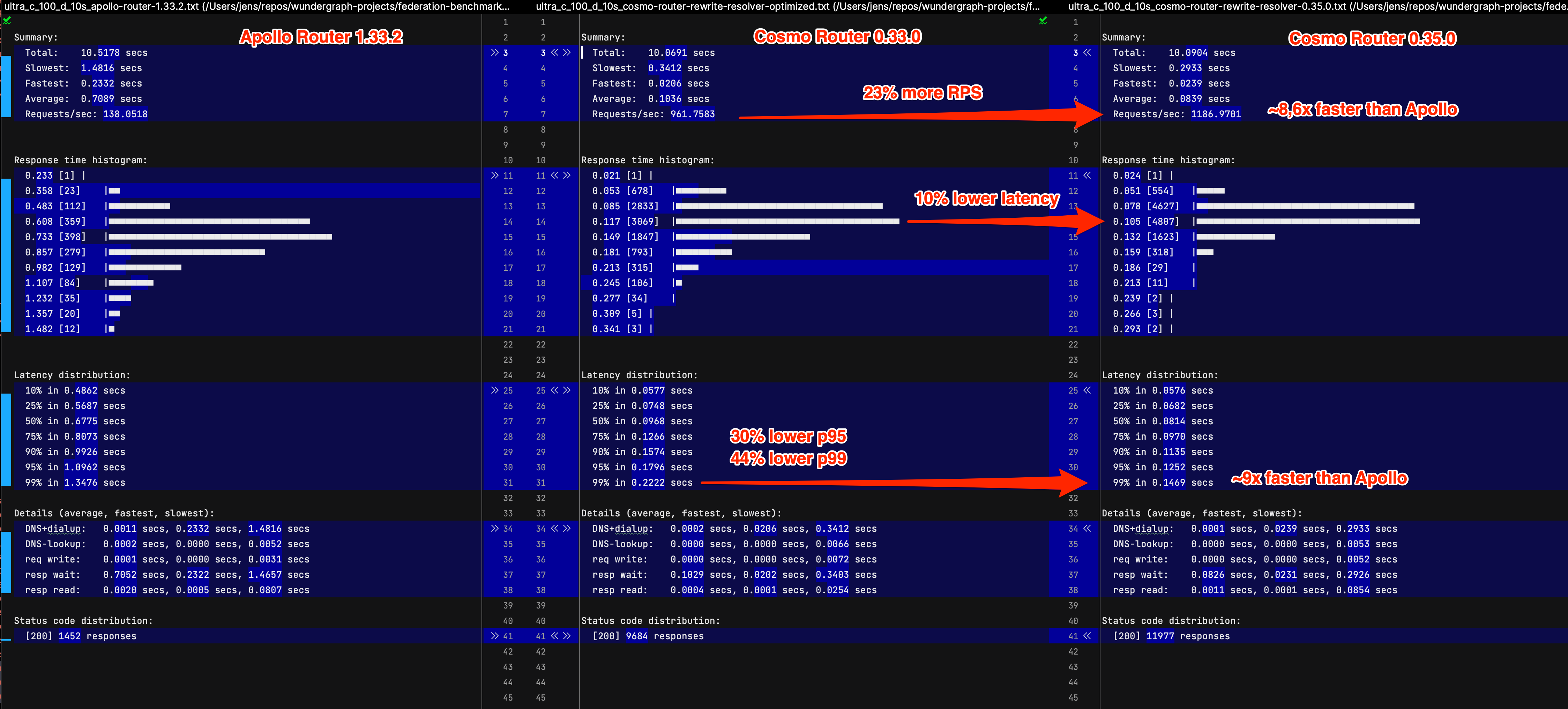
By leveraging the astjson package, we were able to speed up our GraphQL API Gateway (Cosmo Router ) while reducing the memory footprint. At the macro level, we were able to increase requests per second by 23% and reduced p99 latency by 44% over the previous version of Cosmo Router. At the micro level, we reduced the memory usage of a benchmark by 60%.
For comparison, we benchmarked the Cosmo Router against the Apollo Router, which is written in Rust. Our benchmark showed that Cosmo Router, although written in Go, has 8.6x higher throughput and 9x lower latency than the Apollo Router on a 169kb JSON response payload. With smaller payloads, the difference is slightly smaller, but still significant.
As we've seen a reduction in p99 latency by 44% compared to the previous version of the Cosmo Router, we are confident that the astjson package is a significant contributor to the performance improvements.
We're hiring!
We're looking for Golang (Go) Developers, DevOps Engineers and Solution Architects who want to help us shape the future of Microservices, distributed systems, and APIs.
By working at WunderGraph, you'll have the opportunity to build the next generation of API and Microservices infrastructure. Our customer base ranges from small startups to well-known enterprises, allowing you to not just have an impact at scale, but also to build a network of industry professionals.
Why we needed astjson and what problem does it solve for us?
At WunderGraph, we are building a GraphQL API Gateway, also known as a Router. The Router is responsible for aggregating data from multiple Subgraphs and exposing them as a single GraphQL API. Subgraphs are GraphQL APIs that can be combined into a single unified GraphQL API using the Router.
When a client sends a GraphQL Operation to the Router, the Router will parse it and use its configuration to determine which requests to send to which Subgraph. When the data comes back from the Subgraphs, the Router will merge the result with other results. It's often the case that some requests depend on the result of other requests.
Here's a typical pattern of the request pipeline:
- The Router receives a GraphQL Request from a client
- It makes a request to one Subgraph to fetch the data for a root field
- It then drills into the result and makes 3 more requests in parallel to fetch the data for the nested fields
- It merges all of the results and drills even deeper into the merged data
- It makes 2 more requests to fetch the data for the nested fields
- It merges all of the results
- It renders the response and sends it back to the client
In a previous post, we've written about Dataloader 3.0 and how we're using breadth-first data loading to reduce concurrency and the number of requests to the Subgraphs.
In this post, we will expand on that and show you how we're using the new astjson package to efficiently transform and merge JSON objects during the request pipeline. Let's start by looking at some of the benchmarks we've run and then dive into the details of how we're using astjson to achieve these results.
Benchmarks
Cosmo Router 0.33.0 vs Cosmo Router 0.35.0 vs Apollo Router 1.33.2
Cosmo Router 0.33.0 nested batching benchmark without astjson
Memory profile:
CPU profile:
Cosmo Router 0.35.0 nested batching benchmark with astjson
Memory profile:
CPU profile:
Analyzing the CPU and Memory Profiles
Let's have a close look at the profiles and see what we can learn from them.
If we look at the memory profile of 0.33.0, we can see that it's dominated by the jsonparser.Set function as well as mergeJSONWithMergePath and resolveBatchEntityFetch. All of them make heavy use of the jsonparser package to parse, transform and merge JSON objects.
If we compare this to the memory profile of 0.35.0, we can see that the jsonparser package is no longer visible, and the memory usage for resolving batch entities has been significantly reduced.
If we look at the CPU profiles, we can see that they are dominated by runtime calls like runtime.usleep and runtime.pthread_cond_wait. This is because we're using concurrency to make requests to the Subgraphs in parallel. In a benchmark like this, we're sending unrealistic amounts of requests, so we simply need to ignore the runtime calls and focus on the function calls from our code.
What we can see is that the jsonparser package is visible in the CPU profile of 0.33.0 but not in the CPU profile of 0.35.0. In addition, 0.33.0 shows mergeJSON witch significant CPU usage, while 0.35.0 really only shows (*Group).Do which is sync group to handle concurrency.
We can summarize that 0.33.0 spends a lot of CPU time and memory to parse, transform and merge JSON objects using the jsonparser package. In contrast, 0.35.0 seems to have eliminated the jsonparser package from the critical path. You might be surprised to hear that 0.35.0 still uses the jsonparser package, just differently than 0.33.0.
Let's have a look at the code to see what's going on.
How does the astjson package work?
You can check out the full code including tests and benchmarks on GitHub . It's part of graphql-go-tools , the GraphQL Router / API Gateway framework we've been working on for the last couple of years. It's the "Engine" that powers the Cosmo Router.
Here's an example from the tests to illustrate how the astjson package can be used:
The fundamental idea behind the astjson package is to parse the incoming JSON objects into an AST exactly once, then merge and transform the ASTs as needed without touching the actual JSON content. When we're done adding, transforming and merging the ASTs, we can print the final result to a buffer.
Before this, we were using the jsonparser package to parse each JSON object, merge it with the parent JSON object into a new JSON object, then drill into the resulting JSON object and merge it with other JSON objects. While the jsonparser package is very fast and memory efficient, the amount of allocations and CPU time required to parse, transform and merge JSON objects adds up over time.
At some point, I've realized that we're parsing the same JSON objects over and over again, only to add a field or child object to it and then parse it again.
Another improvement we've made is to not even print the result to a buffer anymore. In the end, we have to use the AST from the GraphQL Request to define the structure of the JSON response. So instead of printing the raw JSON to a buffer, we've added another package that traverses the GraphQL AST and JSON AST in parallel and prints the result into a buffer. This way, we can avoid another round of parsing and printing the JSON. But there's another benefit to this approach!
How the astjson package simplifies non-null error bubbling
In GraphQL, you can define fields as non-null. This means that the field must be present in the response and must not be null. However, as we are merging data from multiple Subgraphs, it's possible that a field is missing in the response of one Subgraph, so the Gateway will have to "correct" the response.
The process of "correcting" the response is called "error bubbling". When a non-null field is missing, we bubble up the error to the nearest nullable parent field and set the value to null. This way, we can ensure that the response is always valid. In addition, we add an error to the errors array in the response, so the client can see that there was an error.
How does the astjson package help us with this? As explained earlier, we're using the astjson package to merge all the results from the Subgraphs into a huge JSON AST. We then traverse the GraphQL AST and the JSON AST in parallel and print the result into a buffer. Actually, this was the short version of the story.
In reality, we walk both ASTs in parallel and "delete" all the fields that are not present in the GraphQL AST. As you might expect, we don't actually delete the fields from the JSON AST, we only set references to the fields to -1 to mark them as "deleted". In addition, we check if a field is nullable or not, and if it's not nullable and missing, we bubble up the error until we find a nullable parent field. All of this happens while we're still just walking through the ASTs, so we haven't printed anything to a buffer yet.
Once the "pre-flight" walk through both ASTs is done, all that's left to do is to print the resulting JSON AST to a buffer.
How does the astjson package perform?
Here's a benchmark from the astjson package:
This benchmark parses 4 JSON objects into the JSON AST, merges them into a single JSON Object and prints the result to a buffer.
Here are the results:
As you can see, we're able to eliminate all allocations, making this operation very garbage collector friendly.
Conclusion
In this article, we've introduced you to the astjson package and shown you how we're using it to speed up our GraphQL API Gateway. It allows us to parse each incoming JSON object exactly once, then merge and transform the JSON AST, and finally print the result to a buffer.
As we've seen in the benchmarks, this approach doesn't just look good on paper, it actually helps us to reduce the CPU time and memory usage of our GraphQL API Gateway, which in turn allows us to increase the throughput and reduce the latency.
As a side effect, the code is now much simpler and easier to understand. Especially the non-null error bubbling logic is much easier to implement and understand.
If you found this article interesting, consider following me on Twitter .
